Dernière mise à jour : 2026-06-18
Chaque équipe qui intègre une API d'enrichissement compare les mêmes choses : endpoints, couverture, prix par appel. Presque aucune ne compare les deux variables qui décident vraiment si l'intégration tient en production : la fiabilité et la qualité de la donnée. Ce rapport benchmarke l'état des API d'enrichissement en 2026 : la taille et la croissance du marché, le calcul de disponibilité composite qui érode l'uptime en silence, la réalité des SLA d'enrichissement, et pourquoi une donnée fraîche et juste compte plus que le nombre d'endpoints affichés.
La thèse est qu'une API d'enrichissement ne vaut que par sa propriété de production la plus faible, et que cette propriété n'est presque jamais la liste d'endpoints. Une API rapide qui sert une donnée périmée produit des réponses sûres d'elles et fausses à l'échelle. Une API riche en fonctionnalités mais indisponible au moment de l'appel ne produit rien. La fiabilité et la qualité de la donnée, pas l'étendue, sont les critères qui survivent au contact de la production, et ce sont ceux autour desquels ce rapport est construit.
Le marché des API d'enrichissement en 2026
Le marché croît régulièrement, tiré par la demande de donnée propre pour alimenter l'IA. Les estimations d'études de marché de Mordor Intelligence situent le marché mondial de l'enrichissement de données à environ 2,57 milliards de dollars en 2024, vers environ 4,65 milliards d'ici 2029, à près de 12,5 pour cent par an ; Grand View Research projette une trajectoire similaire, atteignant le milieu des 4 milliards d'ici 2030, à environ 10 à 12 pour cent de CAGR. Les chiffres exacts varient selon le cabinet, mais la direction est sans ambiguïté : l'enrichissement devient une infrastructure.
Le moteur de la demande mérite d'être nommé. À mesure que les organisations déversent du budget dans l'IA, la valeur de cette dépense est plafonnée par la qualité de la donnée qui l'alimente, ce qui fait passer l'enrichissement d'une finesse de sales-ops à un prérequis des initiatives IA. Ce basculement explique pourquoi l'enrichissement est de plus en plus consommé comme une API, une dépendance programmatique au sein d'autres systèmes, plutôt que comme un outil autonome qu'un humain opère.
Cela recadre ce que vous achetez réellement. Quand l'enrichissement est une API embarquée dans votre stack, ce n'est plus un outil que vous évaluez sur des fonctionnalités ; c'est une dépendance que vous évaluez sur la fiabilité et la qualité de la donnée, comme vous évalueriez toute autre brique d'infrastructure de production. Le reste de ce rapport la traite ainsi. Les choix d'architecture derrière cela sont couverts dans le guide d'architecture API.
Il y a une conséquence subtile au fait que l'enrichissement devienne une infrastructure : l'acheteur change. La décision était prise par un responsable sales-ops choisissant un outil ; de plus en plus elle revient à une équipe d'ingénierie ou de RevOps choisissant une dépendance, avec toute la rigueur que cela implique. Cette audience pose les questions autour desquelles ce rapport est construit, disponibilité, taux d'erreur, rate limits, fraîcheur de la donnée, plutôt que de regarder quels logos ornent la page d'accueil, et un fournisseur incapable d'y répondre concrètement n'est pas une option sérieuse pour une intégration de production.

Le problème de la disponibilité composite
Voici le chiffre que personne côté acheteur ne calcule. Une seule API annoncée à 99,9 pour cent de disponibilité a droit à environ 8,76 heures d'indisponibilité par an. Pris isolément, ça semble correct. Mais l'enrichissement passe rarement par une seule dépendance : un pipeline typique en chaîne plusieurs, votre code, l'API d'enrichissement, ses sources de données amont, le réseau. La disponibilité se multiplie le long d'une chaîne, donc cinq dépendances indépendantes chacune à 99,9 pour cent donnent environ 99,5 pour cent combinés, soit plus de quatre heures d'indisponibilité supplémentaires par an que vous ne voyez dans aucun SLA isolé.
Ce calcul de disponibilité composite est le facteur le plus négligé de la fiabilité de l'enrichissement. Chaque API supplémentaire que vous empilez dans un pipeline abaisse la disponibilité effective de l'ensemble, car les pannes sont indépendantes et se cumulent. Une équipe qui intègre trois ou quatre fournisseurs d'enrichissement pour maximiser la couverture peut facilement finir avec un uptime réel pire qu'une équipe qui utilise une seule source fiable et large, même si le SLA de chaque fournisseur paraît rassurant.
L'implication pratique est de compter les dépendances, pas seulement de lire les SLA. La bonne question n'est pas quel uptime une seule API promet, mais à quelle disponibilité composite aboutit toute votre chaîne d'enrichissement une fois les maillons multipliés. Moins de dépendances, plus fiables, battent en général plus d'endpoints, car la fiabilité est multiplicative et se dégrade vite. La dimension rate-limits est couverte dans le guide des rate limits.
Il vaut la peine de rendre le calcul composite concret avec un second exemple. Supposons que votre pipeline dépende de votre propre service, d'une API d'enrichissement, et de la source amont de cette API, trois maillons indépendants. Si chacun tourne à 99,9 pour cent, la disponibilité combinée est d'environ 99,7 pour cent, soit près de 26 heures d'indisponibilité par an au lieu des 8,76 qu'impliquait le SLA unique. Ajoutez un quatrième et un cinquième maillon pour courir après la couverture et vous glissez vers 99,5 pour cent et au-delà. La leçon n'est pas que les dépendances sont mauvaises, c'est que chacune a un coût de fiabilité à peser contre la couverture qu'elle ajoute.
La réalité des SLA d'enrichissement
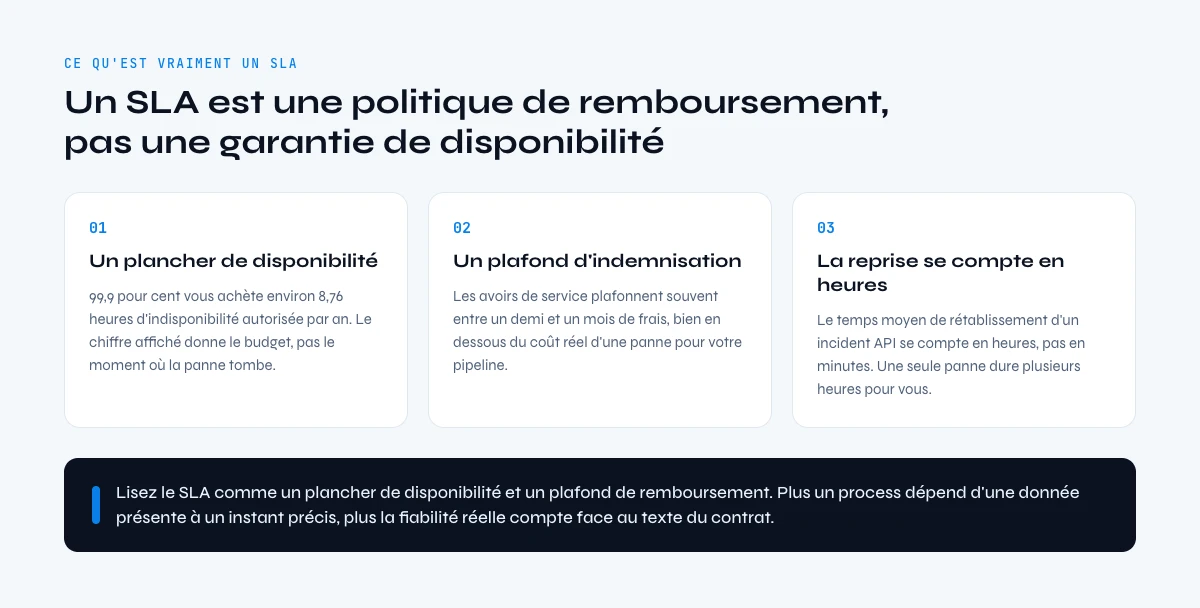
Les SLA sont rassurants sur le papier et faibles en pratique. Les pannes d'API représentent une part majeure des incidents de production, et la récupération n'est pas instantanée : le temps moyen de rétablissement des incidents cloud et API se compte couramment en heures, pas en minutes, donc même la panne d'un fournisseur bien géré est un événement de plusieurs heures pour votre pipeline. Le chiffre de disponibilité affiché vous donne le budget d'indisponibilité ; il ne vous dit pas combien de temps durera une panne quand elle frappe en pleine pointe.
La compensation est faible aussi. La plupart des SLA enterprise qui promettent une haute disponibilité plafonnent leurs crédits de service à une fraction de l'abonnement mensuel, souvent entre la moitié et le mois entier, ce qui veut dire que le remède financier d'une panne est faible face au coût business d'un enrichissement mauvais ou manquant pendant celle-ci. Un SLA est une politique de remboursement, pas une garantie d'uptime, et le remboursement est plafonné bien en dessous de ce que l'indisponibilité vous coûte vraiment.
Lisez donc les SLA pour ce qu'ils sont : un plancher de disponibilité et un plafond de compensation, pas une promesse que la donnée sera là quand vous en aurez besoin. Plus votre processus métier dépend de la disponibilité de l'enrichissement à un moment précis, plus la fiabilité réelle du fournisseur compte par rapport au texte contractuel. Le détail SLA est dans le guide SLA et uptime.

Pourquoi la qualité de donnée bat le nombre d'endpoints
La fiabilité vous apporte la donnée ; la qualité décide si elle valait la peine d'être apportée. Une API d'enrichissement peut être parfaitement disponible et vous remettre quand même des valeurs périmées ou fausses, et une valeur fausse livrée avec un bon uptime est sans doute plus dangereuse qu'une valeur manquante, car elle s'écoule avec assurance dans le scoring, le routage et l'outreach sans déclencher aucune alarme. L'estimation de Gartner d'un coût moyen de la mauvaise qualité de données de 12,9 millions de dollars par an s'applique pleinement quand la mauvaise donnée arrive de façon programmatique, à l'échelle, sans humain dans la boucle pour la contrôler.
C'est pourquoi le nombre d'endpoints est une métrique de vanité. Une longue liste d'endpoints vous dit ce que l'API peut renvoyer, pas à quelle fréquence le renvoi est correct et actuel. Deux API d'enrichissement aux listes d'endpoints identiques peuvent produire des résultats business opposés selon la fraîcheur et l'exactitude de la donnée derrière, et cette différence n'apparaît jamais dans la documentation. Le chiffre qui compte est le match rate à une exactitude acceptable sur la donnée dont vous avez réellement besoin, pas la taille du menu.
La conséquence pour l'acheteur est d'évaluer la qualité de la donnée aussi rigoureusement que la disponibilité. Testez l'API sur vos propres enregistrements, mesurez à quelle fréquence la valeur renvoyée est correcte et actuelle, et pondérez cela bien au-dessus de l'étendue du catalogue d'endpoints. Une API qui fait moins de choses de façon fiable et fraîche vaut plus qu'une qui en fait beaucoup sur une donnée à laquelle vous ne pouvez pas vous fier. Les économies build-or-buy sont dans le guide build vs buy.
Un cadre de décision pour l'acheteur
Évaluez une API d'enrichissement sur six critères, à peu près dans cet ordre d'importance. Un, la qualité de la donnée et le match rate sur vos enregistrements, mesurés, pas annoncés. Deux, la fraîcheur : la donnée est-elle re-vérifiée, ou servie depuis un stock vieillissant. Trois, la disponibilité, y compris la disponibilité composite de toute votre chaîne, pas juste le chiffre unique affiché. Quatre, les rate limits et leur comportement sous votre vrai volume de pointe. Cinq, la posture de sécurité et de conformité. Six, le modèle de prix, idéalement un modèle au crédit transparent qui passe à l'échelle avec l'usage plutôt qu'un palier rigide qui pénalise le petit ou le gros volume.
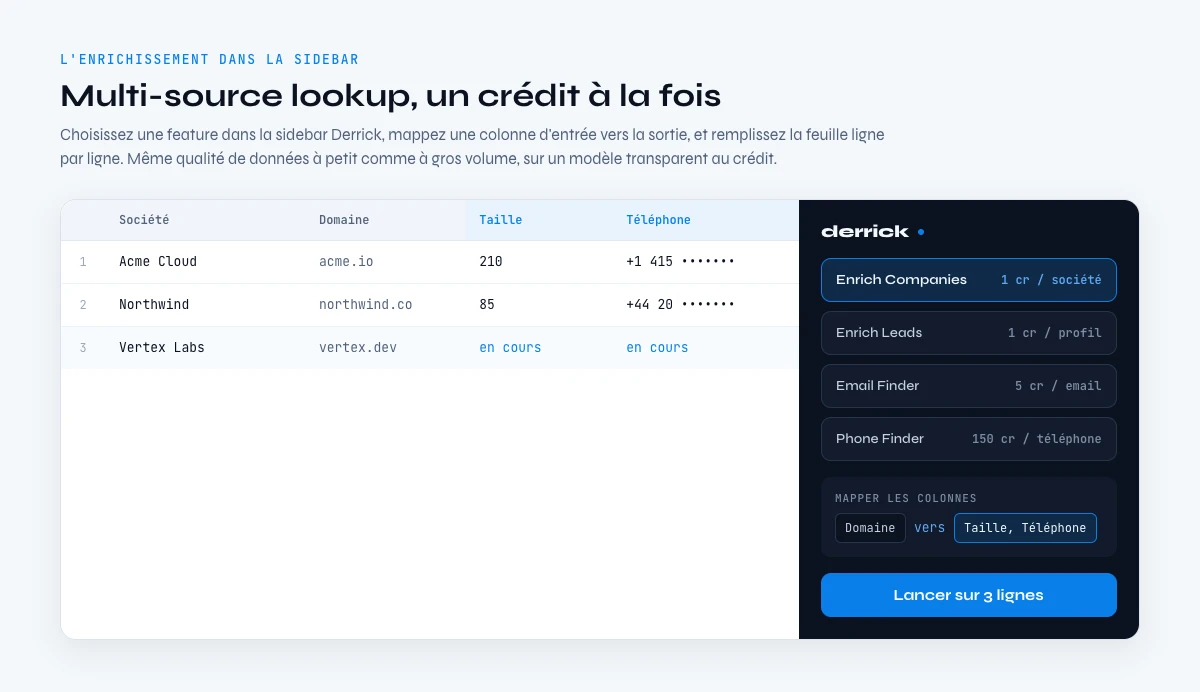
C'est le terrain pour lequel Derrick est conçu. Derrick offre un accès programmatique et API à son multi-source lookup, trouvant et vérifiant emails et numéros de téléphone et enrichissant les données de profil et d'entreprise, avec une disponibilité et une qualité de donnée pensées pour tenir à l'échelle, petit volume comme gros. Il est consommable en API et via plus de 3000 intégrations par Zapier, Make et N8N, sur un modèle au crédit transparent, pour que la fiabilité et la qualité soient des propriétés du service plutôt que des promesses dans un contrat. Nous ne revendiquons pas un SLA parfait sur le papier ; nous pointons les critères qui décident vraiment une intégration, et nous construisons vers eux.
Évaluez l'enrichissement de Derrick sur la fiabilité et la qualité de la donnée, gratuit jusqu'à 100 crédits par mois, avec un accès API et intégrations sur un modèle au crédit transparent. Commencez par tester le match rate et la fraîcheur sur vos propres enregistrements, puis comptez les dépendances de votre chaîne avant d'ajouter un endpoint de plus. La posture de sécurité est détaillée dans le guide de sécurité API de ce cocon.
Le prix mérite un regard de plus comme signal de fiabilité à part entière. Un modèle rigide par siège ou par palier cache souvent le vrai coût de l'échelle : vous payez une capacité inutilisée à faible volume et heurtez des murs à fort volume, deux situations qui ne collent pas à la façon dont la consommation d'API se comporte réellement. Un modèle au crédit transparent aligne le coût sur l'usage, ce qui est à la fois plus juste et le signe que le fournisseur s'attend à être mesuré sur un volume variable, l'état normal d'une intégration de production.
Méthodologie et sources
Ce rapport agrège des sources primaires hors-métier : Mordor Intelligence et Grand View Research pour la taille et la croissance du marché de l'enrichissement ; Gartner pour le coût de la mauvaise qualité de données et les tendances de dépense IA ; et des principes publics et mathématiques de disponibilité (99,9 pour cent équivaut à environ 8,76 heures d'indisponibilité par an, et les disponibilités indépendantes se multiplient le long d'une chaîne de dépendances). Les chiffres d'uptime et d'incidents sont présentés comme des principes établis du secteur plutôt que comme des affirmations de fournisseur. Quand une statistique ne se traçait que via le marketing d'un fournisseur de données ou d'enrichment, nous ne l'avons pas utilisée.
Une dernière réflexion pour qui intègre de l'enrichissement. La tentation est de choisir sur l'étendue, la plus longue liste d'endpoints, le plus de points de données, le plus gros catalogue. La production récompense la discipline inverse : choisir sur la fiabilité et la qualité de la donnée, compter ses dépendances, mesurer la fraîcheur sur ses propres enregistrements, et traiter le SLA comme un plancher plutôt qu'une promesse. Une API d'enrichissement est désormais une infrastructure, et une infrastructure se juge à sa présence et à sa justesse au moment de l'appel, pas à ce qu'elle pourrait théoriquement faire. Bâtissez l'intégration sur ce standard et l'étendue se règle d'elle-même.
Questions fréquentes
Quelle est la taille du marché des API d'enrichissement en 2026 ?
Qu'est-ce que la disponibilité composite ?
Les SLA d'enrichissement protègent-ils vraiment ?
Le nombre d'endpoints est-il un bon critère de choix ?
Comment Derrick se positionne-t-il comme API d'enrichissement ?
À lire aussi dans ce cocon
Lancez votre enrichissement en 30 secondes
Gratuit, 100 crédits/mois. Sans carte bancaire.
Installer Derrick gratuitement →