Dernière mise à jour : 2026-06-18
L'instinct en donnée B2B est d'enrichir tout : chaque champ qu'un fournisseur propose, chaque attribut qu'un enregistrement peut porter. Ce rapport soutient, chiffres à l'appui, que cet instinct est faux. La valeur d'un enregistrement prospect tient à une poignée d'attributs actuels et à fort levier, pas au nombre de champs qui y sont attachés. Nous cartographions les sept familles d'attributs B2B, notons chacune sur la fraîcheur, la disponibilité et l'impact business, et montrons pourquoi un enregistrement léger de champs frais bat un enregistrement gonflé de champs périmés.
La thèse sous-jacente est que la vraie contrainte n'est pas combien d'attributs vous pouvez collecter, c'est si les rares qui comptent sont disponibles et actuels au moment où vous agissez. La disponibilité de la donnée, obtenir le bon champ à la source quand vous en avez besoin, est le goulot, pas la quantité de champs. Un enregistrement avec trente champs périmés vaut moins qu'un enregistrement avec les cinq qui décident du deal, vérifiés aujourd'hui.

Les sept familles d'attributs
Les attributs de donnée B2B se rangent en sept familles, chacune avec un but et une durée de vie distincts. Le firmographique (secteur, taille, localisation) décrit l'entreprise. Le contact et démographique (nom, poste, email vérifié, téléphone direct) permet de joindre réellement une personne. Le technographique (les outils qu'une entreprise utilise) signale l'adéquation et le timing. Le financier (revenu, levée de fonds) dimensionne l'opportunité. Le comportemental et intent (activité de recherche) suggère la maturité. Le timing et triggers (changements de poste, levées, recrutement) signale une fenêtre d'achat. Les attributs personnalisés captent ce dont votre modèle a besoin.
Notées honnêtement, ces familles diffèrent fortement sur les trois axes qui comptent. La donnée de contact est la plus à fort impact et la plus périssable, un email et un téléphone vérifiés sont ce qui transforme une cible en conversation, et ils se périment le plus vite. Le timing et les triggers ont la plus haute valeur décisionnelle mais seulement dans une fenêtre étroite. Le firmographique et le technographique sont modérément stables et largement utiles. Le comportemental et l'intent sont puissants mais durs à sourcer proprement. Le personnalisé est à forte valeur quand il existe et souvent le plus dur à obtenir.
L'intérêt de la carte est de cesser de traiter les attributs comme une liste plate à maximiser et de commencer à les traiter comme un portefeuille à prioriser. Les familles dont vous avez le plus besoin sont en général les plus dures à garder fraîches, et c'est exactement pourquoi la disponibilité, pas la quantité, est le bon angle. La couche contact est détaillée dans le guide des attributs de contact essentiels.
Une façon utile de lire la carte est de combiner l'impact et la périssabilité. Les attributs à la fois à fort impact et à péremption rapide, la donnée de contact avant tout, sont ceux qui exigent un process de re-vérification plutôt qu'une capture unique. Les attributs à fort impact mais stables, comme le firmographique de base, peuvent être captés moins souvent. Et les familles à faible impact, si faciles à collecter soient-elles, méritent le moins d'investissement quelle que soit la complétude que le fournisseur leur donne. C'est l'impact multiplié par la périssabilité, pas le nombre brut, qui devrait piloter où vous dépensez.

Le coût caché des mauvais attributs
Avant d'optimiser quels champs collecter, il aide de chiffrer ce que coûtent les mauvais champs. Gartner estime que la mauvaise qualité de données coûte aux organisations en moyenne 12,9 millions de dollars par an, et a situé l'impact sur le chiffre d'affaires autour de 15 pour cent. Les recherches d'Experian vont plus loin, attribuant jusqu'à un quart du chiffre d'affaires potentiel perdu à cause d'une donnée de mauvaise qualité une fois comptés l'effort mal dirigé et les décisions prises sur de mauvais inputs.
La statistique la plus révélatrice est qu'une large majorité d'organisations, environ 60 pour cent dans les travaux de Gartner, ne mesure pas du tout le coût de sa mauvaise donnée. On ne peut pas gérer ce qu'on ne mesure pas, et un coût de donnée non mesuré est exactement pourquoi le problème persiste trimestre après trimestre : il n'apparaît jamais comme une ligne, seulement comme un chiffre mou quelque part en aval qu'on impute à autre chose.
Cela recadre la question des attributs en question économique. Chaque champ que vous collectez et croyez est un petit pari qu'il est correct ; un champ faux n'est pas neutre, il porte un coût qui se propage dans la segmentation, le routage et l'outreach. L'objectif n'est donc pas la couverture maximale mais l'exactitude maximale sur les champs qui pilotent les décisions, une optimisation très différente. Un simple audit en cinq questions, couvert en Partie 05, fait remonter où se cache votre coût non mesuré.
Le paradoxe de la sur-enrichissement
Voici le constat contre-intuitif. Un enregistrement bourré de dizaines d'attributs ne convertit pas mieux qu'un enregistrement plus léger avec les bons quelques-uns, et convertit souvent moins bien, car les champs en trop ajoutent du bruit, du coût et de la surface de péremption sans ajouter de valeur de décision. Chaque attribut que vous stockez est quelque chose qui peut se périmer et induire en erreur ; empiler des champs à faible valeur ne fait qu'élargir la zone où votre donnée peut être fausse.
La short-list à fort levier est courte. Pour la plupart de l'outreach B2B, les attributs qui bougent vraiment l'aiguille sont un moyen vérifié de joindre la bonne personne, assez de contexte firmographique et technographique pour confirmer l'adéquation, et un signal de timing pour savoir quand. C'est une poignée de champs, tenus à jour, pas cent champs captés une fois. Au-delà de cette short-list, les attributs additionnels montrent des rendements fortement décroissants et un coût de maintenance croissant.
C'est pourquoi la sur-enrichissement est un piège déguisé en rigueur. Remplir chaque colonne donne une impression de complétude, mais la complétude sur des champs à faible valeur et qui se périment n'est pas de la qualité, c'est juste du volume. Le mouvement discipliné est d'identifier les rares attributs dont vos décisions dépendent réellement et de garder ceux-là vérifiés, plutôt que de courir après un enregistrement à l'air complet qui n'est surtout que du remplissage périmé. Le cœur firmographique de cette short-list est dans le guide des principaux attributs firmographiques.
Le piège de la sur-enrichissement a aussi un coût que la plupart des équipes ne comptent jamais : la maintenance. Chaque champ que vous choisissez de stocker est un champ que quelqu'un promet implicitement de garder à jour, et plus vous portez de champs, plus ils pourrissent en silence parce que personne ne peut tous les rafraîchir. Un enregistrement léger n'est pas seulement moins cher à acheter, il est moins cher et plus honnête à maintenir, car vous ne promettez la fraîcheur que sur la poignée de champs que vous utilisez réellement pour décider.
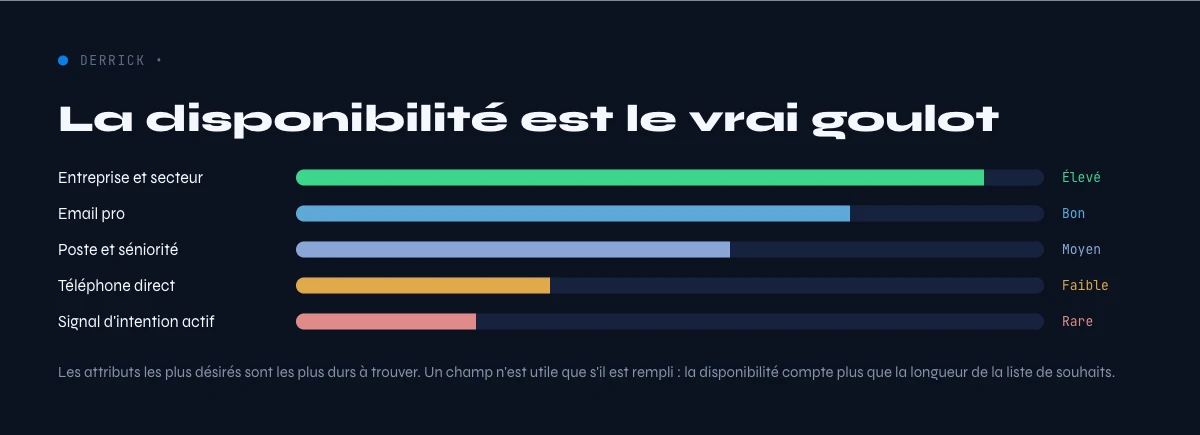
Le vrai goulot : la disponibilité
Si les bons quelques attributs sont ce qui compte, la contrainte devient de les obtenir, avec exactitude, au moment de l'usage. C'est la disponibilité de la donnée, et c'est le vrai goulot que la plupart des équipes étiquettent à tort comme un problème de couverture. Le souci est rarement qu'un attribut ne peut pas être connu ; c'est qu'il n'est pas disponible, frais et correct, là et au moment où vous devez agir dessus. Un champ qui existe dans une base mais est périmé ou hors de portée quand vous agissez est, fonctionnellement, indisponible.
C'est la couche pour laquelle Derrick est conçu. Plutôt que de vendre un fichier statique de tous les champs possibles, Derrick va chercher chaque attribut à la source via un multi-source lookup, l'email et le téléphone vérifiés, les données firmographiques et entreprise, les technologies qu'une entreprise utilise via sa recherche Website Technologies, et l'enrichissement de profil, à la demande et directement dans Google Sheets. Le modèle traite la disponibilité comme le produit : le bon attribut, confirmé au moment de l'usage, plutôt qu'un entrepôt de champs collectés une fois et laissés vieillir.
Cadré ainsi, la stratégie d'attributs et le choix d'outil convergent. Vous n'avez pas besoin d'un fournisseur avec la plus longue liste de champs ; vous avez besoin d'un qui peut rendre les rares attributs dont vous dépendez disponibles et actuels quand vous agissez. C'est une question de sourcing et de fraîcheur, pas de taille de catalogue, et c'est pourquoi la disponibilité est le bon centre de conception d'un programme data. L'angle technographique est détaillé dans le guide de la donnée technographique.
La disponibilité recadre aussi la façon d'évaluer une source de donnée. Le bon test n'est pas combien d'attributs figurent au catalogue, mais avec quelle fiabilité la source renvoie une valeur correcte et actuelle pour les rares attributs dont vous dépendez, sur vos propres enregistrements, à votre propre volume. Une source qui renvoie à chaque fois un email vérifié frais et un profil firmographique confirmé bat une source qui liste cinquante attributs mais est périmée ou vide sur ceux qui décident votre outreach. Mesurez la source sur la short-list, pas sur le catalogue.

La couche timing et un audit en 5 questions
Parmi toutes les familles d'attributs, le timing et les triggers portent la plus haute valeur décisionnelle par champ. Un changement de poste, une levée de fonds ou une vague de recrutement marque un moment où une fenêtre d'achat s'ouvre, et la recherche est claire : les nouveaux dirigeants en particulier sont bien plus susceptibles de faire appel à des prestataires externes à mesure qu'ils remodèlent leur fonction. Le hic est que cette valeur est concentrée dans une fenêtre étroite et n'est réalisable que si la donnée de contact est aussi actuelle ; un trigger travaillé avec un email périmé est une fenêtre manquée, pas un signal.
Utilisez cet audit en cinq questions pour trouver vos propres trous. Un, pouvez-vous énoncer la poignée d'attributs qui pilotent réellement vos conversions ? Deux, savez-vous à quel point chacun est frais en ce moment ? Trois, pouvez-vous joindre la bonne personne aujourd'hui, ou seulement telle qu'au moment où l'enregistrement a été construit ? Quatre, agissez-vous sur les triggers de timing tant que la fenêtre est ouverte ? Cinq, mesurez-vous le coût des champs que vous avez eus faux ? La plupart des équipes ne peuvent pas répondre à au moins deux de ces questions, et ces trous sont là où vit le coût non mesuré.
Derrick soutient directement le haut de gamme de cela : il re-vérifie la donnée de contact à la demande pour qu'un trigger de timing puisse être travaillé avec des coordonnées actuelles, et il enrichit le contexte firmographique et technographique qui confirme l'adéquation, le tout dans le tableur où le travail se fait. Obtenez les rares attributs qui comptent, vérifiés à la demande, avec Derrick, gratuit jusqu'à 100 crédits par mois, directement dans Google Sheets. Le détail des attributs de timing est dans le guide des sales trigger events.
Méthodologie et sources
Ce rapport s'appuie sur des sources primaires hors-métier : Gartner sur le coût de la mauvaise qualité de données (en moyenne 12,9 millions de dollars par an, environ 15 pour cent du chiffre d'affaires, et le constat qu'environ 60 pour cent des organisations ne le mesurent pas) ; Experian sur la part du chiffre d'affaires potentiel perdue à cause d'une donnée de mauvaise qualité ; Harvard Business Review sur les nouveaux dirigeants qui font appel à des prestataires externes ; et Statista, McKinsey et Salesforce pour le contexte macro sur l'adoption data et la productivité commerciale. La péremption est évoquée comme une tendance générale plutôt qu'avec un chiffre précis, car les statistiques de décay facilement disponibles dans ce domaine remontent au marketing de fournisseurs de données, que nous ne citons délibérément pas.
Une dernière réflexion. L'industrie de la donnée vend l'étendue, la plus longue liste d'attributs, car l'étendue est facile à afficher et à comparer. La production récompense l'inverse : une short-list des attributs dont vos décisions dépendent réellement, gardés disponibles et actuels au moment où vous agissez. Cartographiez vos sept familles, trouvez la poignée qui bouge vos conversions, mesurez ce que coûtent les mauvais, et investissez dans la disponibilité plutôt que l'accumulation. L'enregistrement qui gagne n'est pas celui avec le plus de champs, c'est celui dont les rares champs décisifs sont justes quand vous les utilisez.
Questions fréquentes
Quelles sont les familles d'attributs de donnée B2B ?
Faut-il enrichir le plus de champs possible ?
Quel est le vrai goulot de la donnée B2B ?
Combien coûte la mauvaise donnée ?
Quels attributs ont la plus forte valeur ?
À lire aussi dans ce cocon
Lancez votre enrichissement en 30 secondes
Gratuit, 100 crédits/mois. Sans carte bancaire.
Installer Derrick gratuitement →