Last updated: 2026-06-18
Most B2B teams treat their database as an asset that holds its value. It does not. The moment a record is stored, it starts to drift away from reality, people change jobs, companies move, mailboxes close. This report puts numbers on that drift: how fast B2B data decays, what poor quality actually costs, and the one principle that separates a list that stays accurate from one that quietly rots.
These are the canonical figures we reference across every Derrick data report, sourced from primary research rather than vendor marketing. Use them as the baseline to benchmark your own database against.
How fast B2B data decays
B2B contact data decays at roughly 2.1% per month, which compounds to about 22.5% per year (MarketingSherpa). Gartner places the global business-data decay rate near 3% per month, and under high-churn conditions annual decay can climb far higher. Whichever end of the range you sit at, the conclusion is the same: a database left untouched for a year has lost a fifth to a third of its accuracy.
Decay is not uniform across data types. Behavioral and intent signals expire fastest, often within weeks. Contact-level fields, email, direct phone, job title, follow the headline 2 to 3% monthly rate, driven mainly by job changes. Firmographic fields, industry, headquarters, employee count, drift more slowly but still meaningfully as companies grow, merge, and relocate. A single refresh cycle that treats all fields the same will always over-spend on the stable ones and under-refresh the volatile ones.
The decay rate is driven mostly by people moving. Annual job-change rates for professionals run in the 20 to 30% range, and in high-growth sectors like software, agencies, and professional services they run higher. A single move can break an email pattern, a direct dial, a reporting line, and a job title all at once, which is why contact records degrade faster than the company records they hang off. Seniority compounds it: the more senior the contact, the more consequential and frequent the moves, so your highest-value records are often your least stable.
This is why a single decay number for the whole database is a fiction. You have several decay curves running at once, contact-level fields shedding 2 to 3% a month, firmographics drifting slowly, behavioral signals expiring in days. A maintenance plan that applies one cadence to all of them will always be wrong in two directions at the same time, paying to re-verify stable fields while letting the volatile ones rot. The fix is to segment the database by volatility and match refresh frequency to each curve.

What poor data quality actually costs
Gartner estimates that poor data quality costs organizations an average of 12.9 million dollars per year. The damage is rarely a single line item: it shows up as wasted sending reputation, reps working dead records, misrouted leads, and decisions made on numbers that were never true. Validity found that 44% of companies lose more than 10% of annual revenue to CRM data decay alone.
The hidden tax is time. When a meaningful share of records is wrong, every downstream team pays to work around it, sales reps re-researching contacts, marketing suppressing bounces, ops reconciling duplicates. The cost compounds because bad data does not announce itself; it passes silently into campaigns, forecasts, and AI models that then amplify the error at scale.
That amplification is the part most teams underestimate in 2026. An AI model or an automation does not know a field is stale; it treats every input as true and acts on it at machine speed. Feed it a database that is a fifth wrong, and it will personalize to the wrong person, score the wrong account, and route the wrong lead, thousands of times, with full confidence. The better the automation, the faster bad data becomes bad action. Data quality is no longer a back-office hygiene task; it is the input layer that decides whether your AI and automation create leverage or just scale your errors.
The revenue line is the one executives feel. Beyond the average 12.9 million dollar cost, the everyday version is simpler: a campaign sent to a list that is 20% wrong reaches 20% fewer real people, and the sending reputation damage from those failures suppresses the 80% that were valid. Bad data does not just waste the wrong records, it quietly taxes the good ones too.
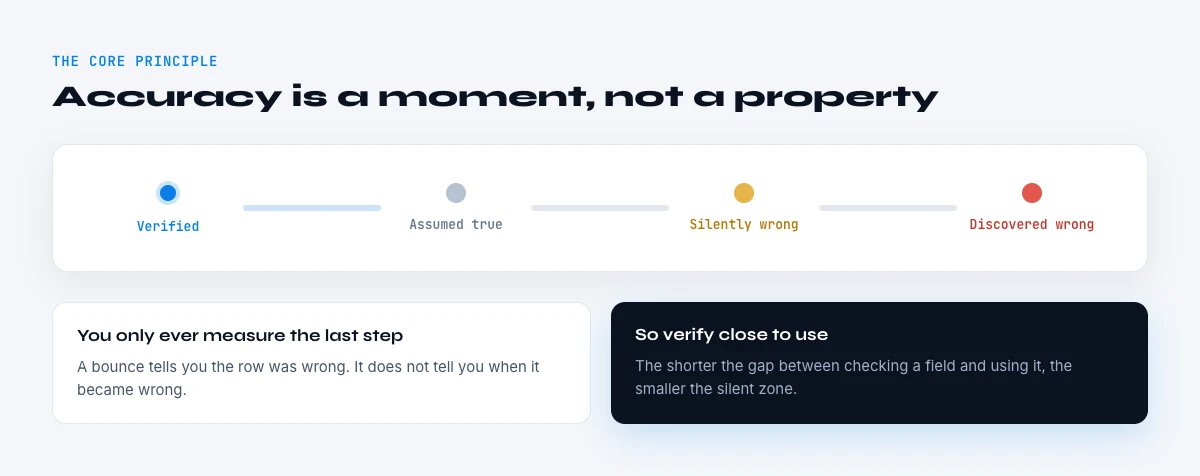
The core principle: accuracy is a moment, not a property
Here is the idea that reframes the whole problem. Accuracy is not something a record has; it is something a record has at a moment in time. A contact verified today is accurate today. The same contact pulled from a static database six months from now carries six months of unverified drift, even if nothing in the file looks different.
This is why two databases with identical fields can perform completely differently. One was built from a stored snapshot and trusted as-is; the other re-verifies each record at the moment it is actually used. Data checked in real time, at the point of use, does not decay between refreshes, because there is no gap between when it was confirmed and when it was acted on. A stored snapshot, by definition, decays from the instant it is written. The most reliable database is not the biggest or the freshest on paper, it is the one verified closest to the moment you act on it. For the metrics behind this, see how to measure data accuracy and why data freshness beats raw volume.
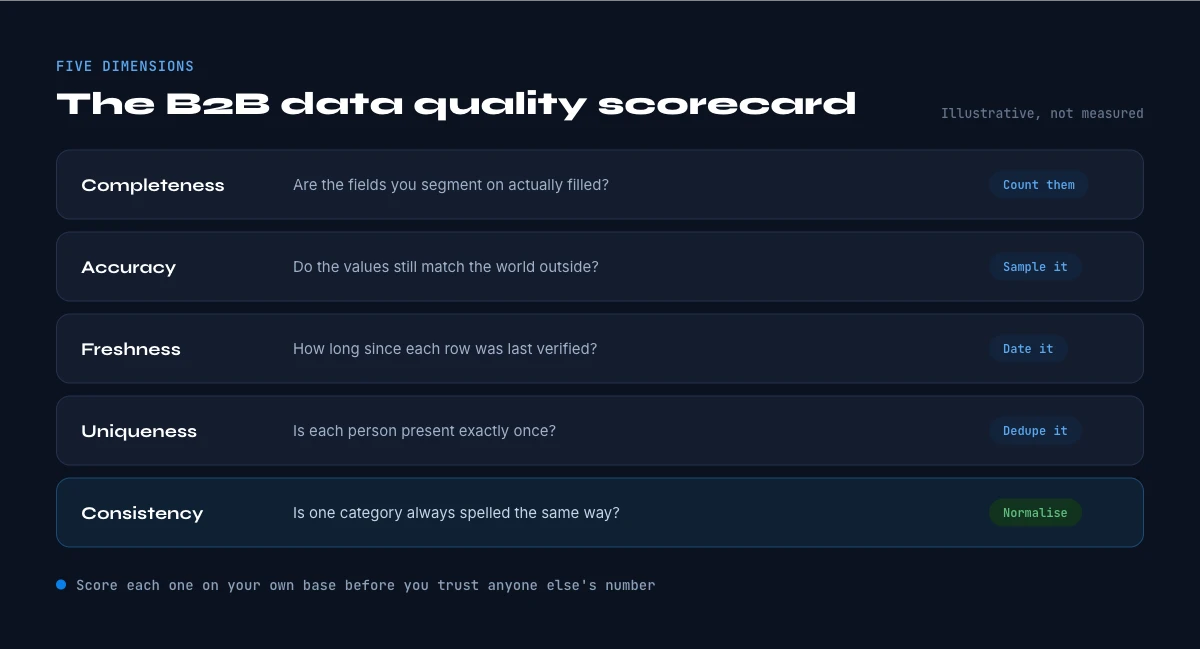
The B2B data quality scorecard
To benchmark a database, score it on five dimensions rather than a single "is it good" judgment. Accuracy: does the field match reality right now. Completeness: what share of records have the fields you need. Freshness: how long since each record was verified. Validity: is the value well-formed and deliverable. Consistency: do the same entities agree across systems. A record can be complete and consistent yet wrong, which is why accuracy and freshness carry the most weight.
Run the self-assessment on this page to position your own database against the 2026 baselines, then translate the gaps into a refresh plan. A useful target: keep verified-within-90-days coverage above 80% on the fields that drive revenue, and treat anything unverified for over a quarter as suspect. A confidence score per record makes this operational rather than a once-a-year audit.
Three mistakes show up again and again when teams grade their data. The first is confusing completeness with accuracy: a fully populated record can be entirely wrong, and a database that looks 100% complete often hides a large share of stale or invalid values. The second is measuring once and assuming it holds: a clean audit in January says nothing about June, because the database has shed months of accuracy in between. The third is trusting the source label over the verification date: where a record came from matters far less than when it was last confirmed against reality.
The cleanest way to see the difference is a simple thought experiment. Take two identical contact lists. Store the first and use it for six months as-is. Verify the second at the moment of each use. On day one they perform the same. By month six the stored list has quietly lost a fifth of its accuracy while the verified one has not, because every record was confirmed at the instant it mattered. Same fields, same source, opposite outcomes, decided entirely by when the data was checked.
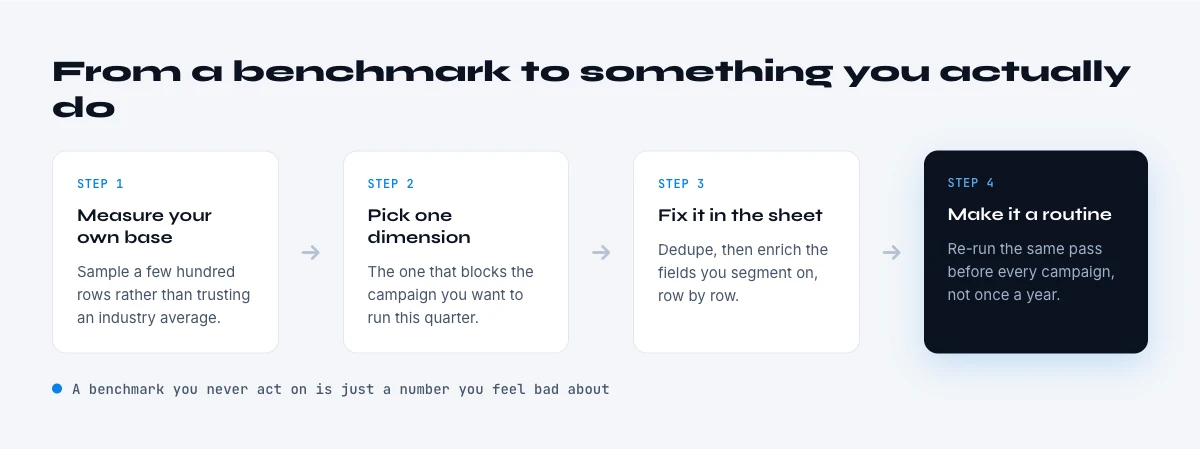
From benchmark to action
Knowing your decay rate is only useful if it changes how you maintain the data. Three moves follow from the numbers. First, set refresh cadence by field volatility, not a blanket annual cleanup: verify contact-level fields far more often than firmographics. Second, verify at the point of use, not just in batch, so the record is confirmed when it matters, not weeks before. Third, measure continuously, a quarterly data audit tells you where you stand, but the goal is to never let a record reach the campaign unverified. The full cost case for closing these gaps is laid out in the cost of missing data.
A practical refresh cadence follows the decay curves, not the calendar. Verify email and direct phone at or near the point of use, because these break with almost every job change and a bounce costs you sender reputation, not just one lost message. Re-check job title and seniority on a monthly to quarterly rhythm for active segments, since a contact who changed roles is effectively a different buyer. Refresh firmographics like headcount, industry, and headquarters on a quarterly to semi-annual basis, fast enough to catch growth and moves without wasting credits on stable fields. Treat behavioral and intent signals as perishable: act within days or let them expire. The rule underneath all of it is simple, verify each field as often as that field actually changes, no more and no less.
Operationally, the highest-leverage move is to push verification as close to the moment of use as possible. A monthly batch cleanup still leaves a record up to a month stale when a rep finally calls it; verifying on demand, the instant a record enters a campaign or a workflow, closes that gap entirely. That is the difference between maintaining a database and maintaining accuracy. The first is a chore you perpetually fall behind on as decay outruns your cleanup schedule. The second builds the check into the action itself, so the question is never "how old is this record" but "was it confirmed when we used it". Teams that make that shift stop fighting decay and start ignoring it, because a record that is verified at the point of use has no time to go stale.
The teams that win on data quality are not the ones with the most records. They are the ones whose records are verified closest to the moment of use, so the database reflects reality when a rep, a campaign, or a model actually reads it. Verify and enrich your B2B data on demand with Derrick, free for 100 credits per month, directly inside Google Sheets.
Methodology and sources
The benchmarks in this report aggregate primary research on B2B data decay and data-quality cost, including published figures from Gartner, Validity, and MarketingSherpa, normalized into comparable ranges. Where a statistic could only be traced to secondary commentary, we left it out rather than relay an unverifiable number. Ranges are presented as ranges because decay depends heavily on industry churn, data type, and how the database is maintained. Treat them as the baseline to beat, and re-measure your own numbers rather than assuming the average applies to you.
One closing note on using these numbers. The averages are a starting line, not a verdict on your specific database. Two companies in the same industry can sit at opposite ends of the decay range depending on how much their target market churns and how their data was sourced and maintained. A baseline is useful because it sharpens the question: not "is our data good" in the abstract, but "how far is our verified-within-90-days coverage from the 80% target, and on which revenue-driving fields". Run the self-assessment, get your own figure, and re-run it each quarter, the teams that improve are the ones that turn data quality from an annual opinion into a number they watch the way they watch pipeline or churn.
Finally, be skeptical of any single dramatic statistic, including the ones here. The most-cited data-quality numbers circulate so widely that their original source is often lost, which is exactly how a plausible figure becomes an unverifiable one. We kept only what traces back to primary research and dropped the rest, and you should hold your own reporting to the same standard: a number you cannot source is a number you cannot defend.
Frequently asked questions
How fast does B2B data decay?
What does poor data quality cost?
Should I prioritize data volume or freshness?
How often should a B2B database be refreshed?
How do I measure my data quality?
Continue exploring this cluster
Start enriching your sheet in 30 seconds
Free for 100 credits/month. No credit card.
Install Derrick free →