Last updated: 2026-06-18
Your CRM is the system of record your entire revenue org trusts, and most of what it contains is wrong, missing, or duplicated. This report puts numbers on the state of CRM data in 2026, what the decay actually costs, and why the gap between a clean CRM and a useful one comes down to one thing: whether records are enriched and verified when you use them, not when they were first entered.
The uncomfortable truth is that a CRM is a static store of a moving reality. It is accurate the moment a record is created and drifting from that moment on. Left alone, it does not hold its value; it quietly rots while every forecast, campaign, and rep action keeps treating it as ground truth.
The state of CRM data in 2026
The headline figures are stark. Industry studies suggest that as much as 91% of CRM data can become inaccurate within a year without active maintenance, and 24% of CRM administrators report that less than half their data is accurate and complete. This is not an edge case or a neglected database; it is the normal trajectory of any CRM that is filled once and refreshed rarely.
The reason is structural, not operational. People change jobs, companies move, deals change hands, and none of that updates itself in your CRM. A record entered accurately in January describes a person who, by year end, has a meaningful chance of having moved, been promoted, or left. The CRM does not know, so it keeps presenting last year's facts as current ones, and every team downstream inherits the error without seeing it.
What makes this dangerous is that a CRM looks fine while it rots. The records are still there, the fields are still populated, the dashboards still render. Nothing flags that a fifth of the contacts moved or that a third of the firmographics are out of date. Decay is silent by design, which is why teams routinely overestimate the quality of their CRM until a campaign bounces or a forecast misses. The database does not get visibly worse; it gets quietly wrong, and the only way to know is to measure against reality rather than trust the stored values.
The maintenance most teams rely on makes this worse, not better. Manual updates depend on reps logging changes they often do not notice, and periodic imports refresh a slice of the database while the rest keeps aging. Both assume the CRM is something you fix occasionally, when the reality is that it degrades continuously. A continuous problem cannot be solved by an occasional fix; the cleanup falls behind the decay the day after it runs, and the gap reopens immediately.
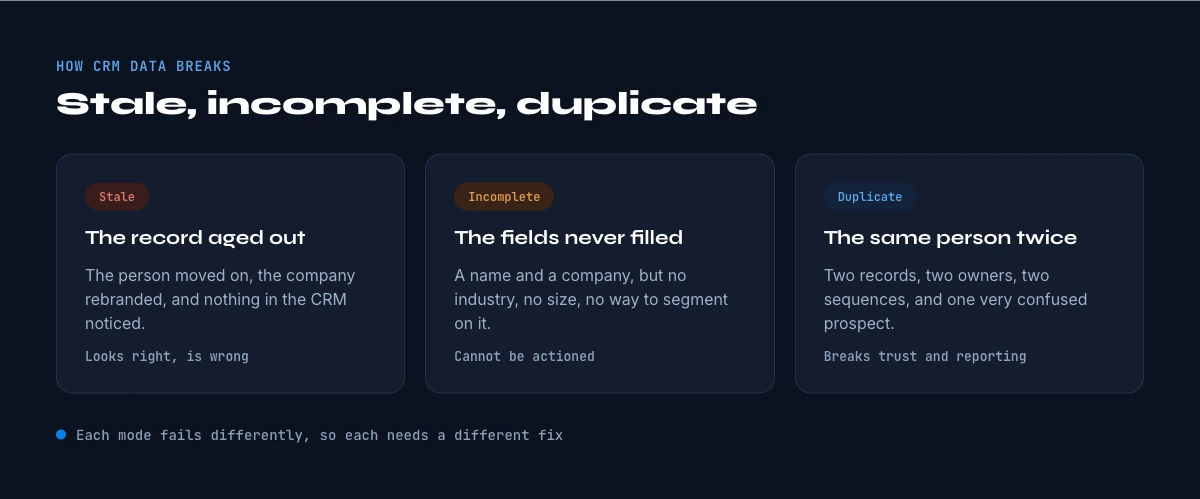
The three failure modes: stale, incomplete, duplicate
CRM data fails in three distinct ways, and a healthy database has to be measured on all three. The first is staleness: B2B contact data decays at roughly 2.1% per month, around 22.5% per year, with work email addresses degrading even faster. The second is incompleteness: industry studies show 30 to 40% of B2B records are missing essential fields like job title or company size, which quietly breaks segmentation, routing, and personalization. The third is duplication: on average 10 to 30% of CRM records are duplicates, inflating counts, splitting histories, and corrupting reporting.
These three compound. A duplicate of a stale, incomplete record is the worst of all worlds, and most CRMs carry all three at once. Crucially, they require different fixes: deduplication is a merge problem, completeness is an enrichment problem, and staleness is a verification problem. A single annual cleanup that treats them as one task will always leave two of the three unaddressed.
The order matters too. Deduplicating before enriching means you enrich fewer records and avoid filling fields on copies you are about to merge. Enriching before verifying means you confirm complete records rather than re-checking half-empty ones. And verifying last, at the point of use, ensures the record is current when it actually gets read. Teams that run these as one undifferentiated "data cleanup" tend to do them in the wrong order and repeat work, which is part of why CRM hygiene feels endless and never quite finished.
It also helps to know which failure mode hurts most for your motion. High-volume outbound is punished hardest by staleness and bad emails, because bounces compound into deliverability damage. Account-based selling is punished hardest by incompleteness, because missing firmographics break targeting and routing. Reporting and forecasting are punished hardest by duplication, because split records distort every aggregate. Diagnosing which mode dominates your pain tells you where to spend first.
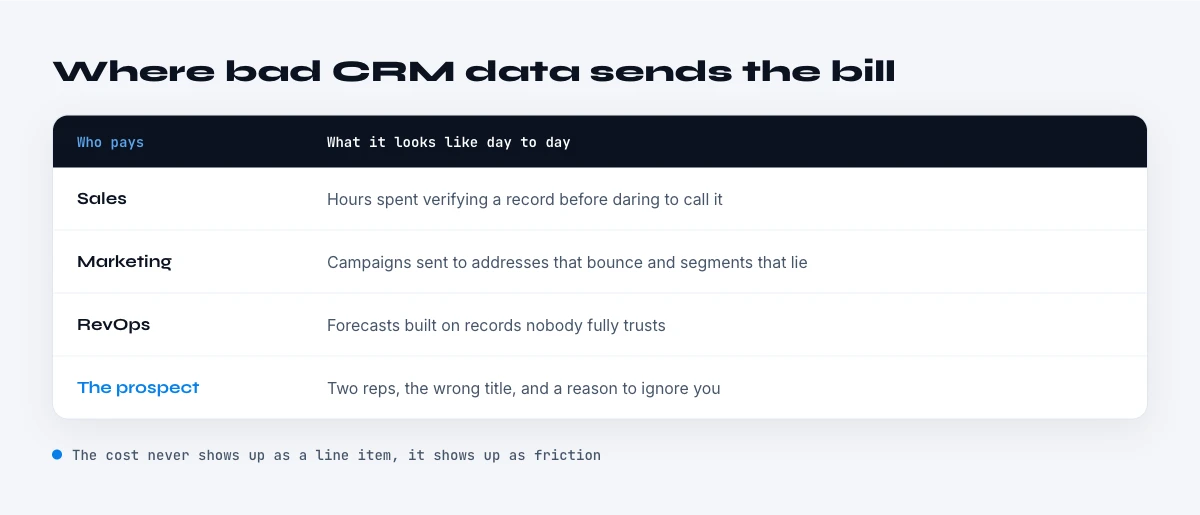
What bad CRM data actually costs
Gartner estimates poor data quality costs organizations an average of 12.9 million dollars per year, and Validity found that 44% of companies lose more than 10% of annual revenue to CRM data decay alone. The damage is not abstract: it is reps calling dead numbers, leads routed to the wrong owner, forecasts built on duplicated or stale pipeline, and marketing spend aimed at people who left.
The most expensive failures are the invisible ones. A forecast built on a CRM that is a fifth wrong is wrong in ways no one can see until the quarter closes. Territory assignments based on stale firmographics send your best reps after companies that no longer fit. And every bounce from an outdated email chips at the sender reputation that the valid contacts depend on. Bad CRM data does not announce itself; it taxes every decision made on top of it.
There is a compounding angle leaders miss: bad CRM data does not just cost money directly, it erodes trust in the system itself. Once reps learn the CRM is often wrong, they stop relying on it, keep their real notes elsewhere, and log the minimum. That makes the data worse, which lowers trust further, in a spiral. A CRM is only as valuable as the confidence the team has in it, and that confidence is bought one accurate record at a time, at the moment of use.
The fix is not heroic data-entry discipline, which never scales, but removing the need for it. When records are enriched and verified automatically at the point of use, reps do not have to maintain the CRM by hand to trust it, because the data is confirmed for them when they read it. Reliability stops depending on human diligence and becomes a property of the workflow, which is the only version of CRM hygiene that survives contact with a busy quarter.
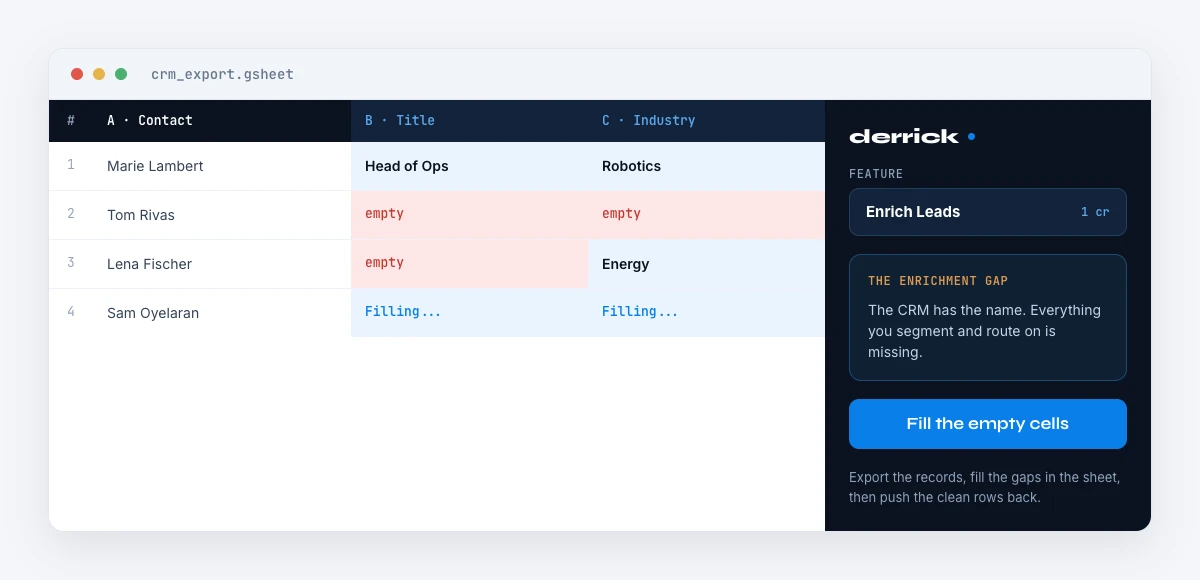
The enrichment gap, and how to close it
Here is the principle that reframes CRM hygiene. A record is accurate at a moment in time, not as a permanent property. The CRM stores the moment of entry; reality has moved on by the moment of use. The gap between those two moments is the enrichment gap, and it is where campaigns and forecasts go wrong. Closing it is not about cleaning the database harder once a year; it is about enriching and verifying each record at the moment you act on it, so the data the rep or the campaign reads is confirmed against reality, not recalled from a stale entry.
This is why two teams on the same CRM platform can have completely different data quality. One treats the CRM as the source of truth and trusts whatever is stored; the other treats the CRM as a working store that gets enriched and re-verified at the point of use, so a missing job title is filled and a stale email is re-checked at the moment it matters. Same platform, opposite reliability, decided entirely by when the data was confirmed. To go deeper on the workflow, see CRM enrichment workflows, and on platform fit, how the major CRMs compare.
Closing the enrichment gap at the point of use also changes the economics of CRM hygiene. A periodic full-database cleanup pays to refresh every record, including the ones no one will touch this quarter, and most of that work has decayed again before it is used. Verifying on demand spends effort only on the records you actually act on, exactly when you act on them, so the cost tracks usage instead of database size. You stop paying to maintain dormant data and start paying to be right at the moment of contact.
This is the quiet difference between a CRM that drags and one that compounds. When records are confirmed at the moment of use, the team trusts the data, forecasts hold, and campaigns reach real people, so the CRM becomes an asset that earns its keep. When records are trusted blindly from storage, every downstream process slowly absorbs the decay, and the CRM becomes a liability dressed as a source of truth. The platform is the same; the discipline of when you verify is what separates the two.

CRM data quality benchmarks and how to act
Score your CRM against four targets that good programs hit: 93% or higher email validity, a duplicate rate under 5%, field completion above 80% on the fields that drive revenue, and a bounce rate under 2%. Most CRMs miss several of these, and the gap from the benchmark is your roadmap. Measure all four rather than a single "is it clean" judgment, because a CRM can be fully deduplicated yet stale, or complete yet wrong.
One caution on benchmarks: hitting them once is not the goal, holding them is. A CRM that passes all four targets in a January audit will fail several by midyear if nothing maintains it, because the same decay that created the gap keeps running. Treat the four numbers as live metrics you watch, not a certificate you earn once. The teams with durably clean CRMs are not the ones who clean hardest in a one-off project; they are the ones who verify continuously, so the metrics never drift far from target in the first place and the cleanup never has to be heroic.
Then act by failure mode, not with one blunt cleanup. Deduplicate with a merge-and-match pass. Close completeness gaps with enrichment that fills missing fields. And beat staleness by verifying at the point of use rather than waiting for a quarterly batch the data outpaces. The cadence should follow volatility: contact fields far more often than firmographics. Enrich and verify your CRM data on demand with Derrick, free for 100 credits per month, directly in Google Sheets, so records are confirmed when your team actually uses them.
Methodology and sources
This report aggregates primary research and independent benchmark studies on CRM data quality, including Gartner's cost-of-poor-data figure, Validity's revenue-impact finding, and the canonical B2B data-decay baseline, alongside published ranges for duplication and incompleteness. Where a statistic could only be traced to a vendor's own marketing, we treated it as a claim rather than a finding and left unverifiable numbers out. Treat the ranges as the shape of the problem, then measure your own CRM against the four benchmarks rather than assuming the average applies to you.
A final note on sourcing. The most dramatic CRM-data statistics circulate widely and lose their origin along the way, so we anchored on figures that trace to primary research and treated single-vendor numbers as claims rather than findings. The point of a benchmark is not to scare you with a big percentage; it is to give you a concrete target to measure against. Whatever the industry average turns out to be, the only number that should drive your roadmap is the one you get when you measure your own CRM, today, on the records that actually drive revenue, and then re-measure it next quarter to confirm it held. A benchmark you check once is a snapshot; a benchmark you watch is a system, and only the second one keeps a CRM clean over time.
Frequently asked questions
How much CRM data is inaccurate?
How many duplicates does a CRM hold on average?
What is the enrichment gap?
What does bad CRM data cost?
What CRM data quality benchmarks should I aim for?
Continue exploring this cluster
Start enriching your sheet in 30 seconds
Free for 100 credits/month. No credit card.
Install Derrick free →